185.
HN
OverflowML – Run AI models larger than your GPU, one line of code
OverflowML is a tool designed to facilitate the execution of AI models that exceed available GPU memory without requiring manual configuration. By automatically detecting the user's hardware—such as NVIDIA, Apple Silicon, or AMD—it implements optimal strategies for loading and running large models efficiently through strategic memory management. This addresses challenges associated with offloading, quantization, and varying hardware combinations, ensuring seamless execution of complex AI tasks.
Modern AI models frequently surpass GPU VRAM capacities (8-24GB), necessitating advanced techniques like CPU offload or model quantization to handle larger sizes, for instance, 40GB image generation models. OverflowML streamlines these processes with minimal user input, allowing the direct running of large models while avoiding common manual configuration issues.
The tool supports multiple platforms including Windows and Linux with NVIDIA CUDA, macOS with Apple Silicon, and CPU-only environments. Its strategy engine autonomously resolves potential incompatibilities by recognizing hardware capabilities and applying suitable memory strategies such as direct GPU loading, FP8 quantization, or sequential CPU offloading, contingent on the model size and resources available.
Installation of OverflowML is straightforward via pip, and it integrates seamlessly with leading AI libraries like Diffusers. It has proven to enhance processing times and reliability significantly, reducing VRAM usage while maintaining high performance and achieving zero failure rates in real production settings.
In summary, OverflowML simplifies the execution of large-scale AI models across diverse hardware configurations by automating complex memory management tasks, thereby making advanced AI workflows more accessible to users.
Keywords: #phi4, AI models, Apple Silicon, CLI, GPU, OverflowML, VRAM, cross-platform support, cross-platform support Keywords: OverflowML, hardware detection, installation, memory strategy, offloading, quantification, quantization, sequential CPU offload, unified memory
 github.com 23 hours ago
github.com 23 hours ago
|
192.
HN
Claude Code makes local LLMs 90% slower
The document serves as a guide for utilizing open language models (LLMs) like Qwen3.5, DeepSeek, and Gemma on local devices through the tool Claude Code, despite acknowledging a 90% reduction in inference speed when running LLMs locally. It outlines necessary setup requirements, such as deploying models using llama.cpp across different operating systems and downloading specific quantized model files from Hugging Face Hub for efficiency. The guide details how to serve these models on port 8001 with llama-server and adjust sampling parameters (temperature, top-p, top-k) according to system capabilities, like a 24GB GPU. For configuring Claude Code to use locally served models, the document advises setting environment variables such as `ANTHROPIC_BASE_URL` and modifying settings in `~/.claude/settings.json`. It also emphasizes ensuring persistent configurations by updating shell profile files and offers additional tips for Windows users using PowerShell commands. Integration with IDEs like VS Code through extensions is suggested to streamline workflow. The guide concludes by acknowledging the significant slowdown inherent in local setups, providing configuration strategies to mitigate performance issues as much as possible.
Keywords: #phi4, Anthropic API key, CPU inference, Claude Code, DeepSeek, GGUF, GPU inference, Gemma, Git workflows, LLMs, Metal support, Qwen35, VRAM, VS Code extension, VS Code extension Comma-separated List: Claude Code, agentic workloads, environment variables, finetuning, finetuning Final Keywords: Claude Code, inference speed, llamacpp, local deployment, open models, quantization, sampling parameters, settingsjson, terminal setup Extracted Keywords: Claude Code, terminal setup Keywords: Claude Code, unsloth
unsloth.ai a day ago
|
217.
HN
Show HN: autoautoresearch – Karpathy's autoresearch on steroids
The project "autoautoresearch" builds on Andrej Karpathy's autoresearch framework to automate AI research using autonomous agents, addressing challenges like the "Blank Page Problem" by introducing a "Creative Director" component that fosters radical experimentation and novelty. The system is structured into directories such as `baseline/` for standard operations and `mad-scientist/` for director-driven exploration, with each experiment method housed in its own directory including scripts and a Go binary "director." This director employs tools like DeepSeek Chat to summarize code states, fetch random ML paper abstracts from arXiv, and generate specific ideas via DeepSeek Reasoner, promoting innovative changes.
Experiments compare control (`baseline`) setups with `mad-scientist` setups that incorporate the director's creative input. Results show improvements when directives are followed or adapted creatively, exemplified by removing logit softcaps and adjusting attention heads to enhance performance. The project has been configured for NVIDIA Jetson AGX Orin hardware, with necessary adaptations for compatibility due to software limitations like Triton.
To set up the environment, users install dependencies, download data, train tokenizers, and run experiments manually or autonomously via agents. Agents modify `train.py` based on instructions from `program.md`, with a fixed 5-minute time budget per experiment to ensure comparability of results. Design choices focus on simplicity, minimal external dependencies, and single-GPU setups, though the fixed time budget limits cross-platform result comparison.
Currently optimized for NVIDIA GPUs, there is interest in adapting "autoautoresearch" for smaller platforms like MacBooks by suggesting reductions in dataset complexity, vocabulary size, sequence length, and model depth. The project encourages community contributions through forks that adapt autoresearch to various environments, showcasing its flexibility and potential for widespread application. Overall, "autoautoresearch" aims to expand AI research horizons by enabling autonomous agents to explore innovative ideas more freely, potentially driving significant advancements in model development.
Keywords: #phi4, AI, AdamW, BPE tokenizer, CUDA, Chaos Monkey, DEPTH, DEVICE_BATCH_SIZE, DeepSeek Chat, Flash Attention 3, GPT model, Go binary, Karpathy, LLMs, ML paper abstract, Muon, NVIDIA Jetson AGX Orin, PyTorch, TOTAL_BATCH_SIZE, VRAM, arxiv, autoautoresearch, autonomous agents, baseline, bits per byte, compute cluster megastructures, dataloader, director-driven exploration, evaluation, experiment iteration, genetic algorithm, hyperparameter search, hyperparameter sweep, mad-scientist, optimizer, programmd, scaled_dot_product_attention, self-modifying binary, training loop, val_bpb
github.com a day ago
|
287.
HN
Show HN: How I Topped the HuggingFace Open LLM Leaderboard on Two Gaming GPUs
In mid-2024, an AI researcher achieved a breakthrough on the HuggingFace Open LLM Leaderboard by developing "LLM Neuroanatomy," a technique that enhanced the performance of a 72-billion parameter language model without changing its weights. The method involved strategically duplicating specific layers within the existing architecture and reintegrating them to boost reasoning capabilities, allowing it to operate efficiently on consumer-grade VRAM using two RTX 4090 GPUs with quantized models.
The innovation was inspired by observations about Transformers' handling of inputs like Base64 encoding and an unexpected architectural feature in the Goliath-120b model. The researcher devised a "Brain Scanner" pipeline to explore various internal layer configurations, identifying that duplicating specific circuits within these layers significantly improved performance on mathematical reasoning and emotional quotient tasks.
The key discovery was that repeating seven layers near the Transformer stack's middle led to notable enhancements across multiple benchmarks without necessitating weight alterations or fine-tuning. This approach challenged conventional LLM architectures by proposing a modular "circuit" method for layer functionality, highlighting how Transformers form distinct processing units during training that specialize in particular cognitive operations.
Further experiments confirmed that duplicating entire reasoning circuits improved performance more effectively than individual layers. These findings prompted additional research and influenced the development of larger models, marking an important contribution to AI model optimization by suggesting a new perspective on enhancing transformer-based architectures through internal structural modifications.
Keywords: #phi4, Base64 Encoding, Brain Scanner, Fine-tuning, Functional Anatomy, Goliath Anomaly, HuggingFace, LLM Leaderboard, Layer Duplication, Mechanistic Interpretability, Open Source Models, RYS-XLarge, Transformers, VRAM
dnhkng.github.io a day ago
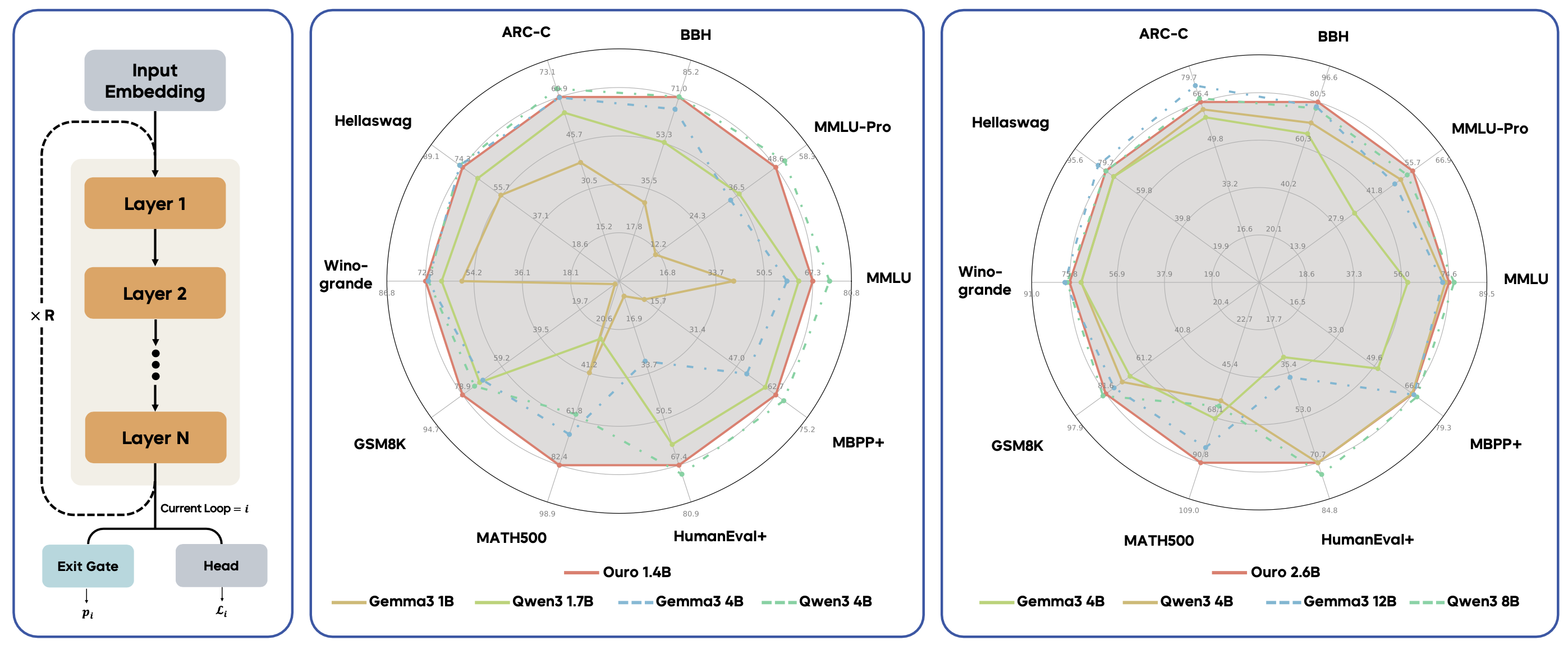
https://ouro-llm.github.io/ a day ago
https://weightwatcher.ai/ a day ago
https://news.ycombinator.com/item?id=46222237 a day ago
https://arxiv.org/abs/2407.09298 a day ago
https://www.alphaxiv.org/abs/2512.19941 a day ago
https://arxiv.org/abs/2510.25741 a day ago
https://youtu.be/GiaNp0u_swU?si=m7-LZ7EYxJCw0k1- a day ago
https://arxiv.org/abs/2312.15166 23 hours ago
https://arxiv.org/abs/2502.05795 23 hours ago
https://arxiv.org/abs/2502.05171 23 hours ago
https://ouro-llm.github.io/static/images/ouro_main 23 hours ago
https://arxiv.org/abs/2401.08741 23 hours ago
https://www.youtube.com/watch?v=pDsTcrRVNc0 23 hours ago
https://dnhkng.github.io/posts/rys/#the-beginning- 23 hours ago
|
556.
HN
High fidelity font synthesis for CJK languages
The zi2zi-JiT model is a specialized tool designed to execute high-fidelity font style transfer specifically for Chinese, Japanese, and Korean (CJK) languages by leveraging the Just Image Transformer (JiT) framework. It achieves this through three main components: a Content Encoder that uses CNNs adapted from FontDiffuser to extract structural layouts of input characters; a Style Encoder that captures stylistic elements from reference glyphs using CNNs; and a Multi-Source In-Context Mixing approach, which concatenates embeddings for content, style, and font to condition the transformation process. The model is available in two variants, JiT-B/16 and JiT-L/16, both trained on an extensive corpus of over 400 fonts that include simplified Chinese, traditional Chinese, and Japanese characters. Training was conducted across 2,000 epochs with evaluations based on metrics such as FID, SSIM, LPIPS, and L1 scores against ground-truth data.
For practical use, the zi2zi-JiT environment is set up via Conda, followed by necessary Python package installations. Pretrained models are accessible from Google Drive in specified formats like `zi2zi-JiT-B-16.pth`. The model supports dataset generation using either font files or rendered glyph images and offers fine-tuning capabilities with LoRA on single GPUs to enhance memory and runtime efficiency.
Character synthesis is facilitated through various sampling methods, with the recommended settings for quick generation being the `ab2` method alongside 20 default sampling steps. Performance evaluation of the model utilizes pairwise metrics such as SSIM, LPIPS, L1, and FID on generated character grids. In terms of licensing, while the code is distributed under an MIT license, any fonts created using the model are subject to a "Font Artifact License Addendum," which permits commercial use with appropriate attribution if more than 200 characters from the repository are incorporated into distributions. The zi2zi-JiT builds upon foundational elements from FontDiffuser for encoder designs and incorporates JiT's diffusion transformer architecture.
Keywords: #phi4, CJK languages, Chinese font style transfer, Content Encoder, FID, Google Drive, JiT (Just image Transformer), L1, LPIPS, LoRA Fine-Tuning, Multi-Source In-Context Mixing, SSIM, Style Encoder, VRAM, conditioning strength, dataset generation, diffusion transformer architecture, environment setup, font synthesis, paired dataset, pretrained checkpoints, rendered glyph images, training epochs, zi2zi-JiT
github.com 2 days ago
|
686.
HN
Show HN: I made Qwen3.5-4B 13% smarter by compressing it to 4-bit
The author introduces the Singularity Principle Index (SPI), a novel technique designed to optimize the Qwen3.5-4B language model through selective layer quantization while maintaining critical layers in full precision. This innovation results in a hybrid model named "Qwen3.5-4B-Singularity-Max," which offers improved performance metrics, including significantly lower perplexity and reduced VRAM usage compared to its fully quantized and original FP16 versions. Key achievements of this approach include a 13.4% reduction in perplexity (from 7.79 to 6.74) and a decrease in VRAM requirements from approximately 16 GB to about 6.4 GB, allowing it to fit consumer GPUs and edge devices more comfortably. Furthermore, the model demonstrates enhanced inference speed with no dequantization overhead, achieving 9.85 tokens per second on a Kaggle T4 instance.
The SPI method strategically identifies critical layers—129 out of the total—using weight matrix spectral decay analysis, ensuring these are preserved in FP16 precision. In contrast, non-critical layers undergo aggressive quantization to 4-bit precision. This selective approach not only acts as a form of regularization by removing overfitting artifacts but also preserves essential model logic. The methodology is elaborated upon in an academic preprint and made available for further experimentation.
This advancement marks a significant shift in deploying large language models (LLMs) on edge devices, presenting a more intelligent and efficient alternative to existing quantization techniques like QLoRA or GPTQ. By enhancing both performance and resource efficiency, the SPI could redefine how local LLMs are utilized in AI applications, particularly those requiring deployment on constrained hardware environments.
Keywords: #phi4, Academic Preprint, Calibration Data, Cognitive Layers, Edge Devices, FP16, Huggingface, Inference Speed, Kaggle T4, LLMs, Low-Precision Neural Networks, Mixed-Precision Hybrid Model, Noise-Canceling Effect, On-Device AI, Overfitting Artifacts, Perplexity, QLoRA, Qwen35-4B, Robustness, SafeFP16Linear, Singularity Principle Index, Spectral Compactness, Spectral Decay, Trace-norm Regularization, VRAM, Zero-shot Surgical Weight Refinement, quantization
huggingface.co 3 days ago
|
691.
HN
Perfect Green Screen Keys
CorridorKey is an advanced neural network-based tool designed to enhance green screen keying by accurately separating foreground objects from green backgrounds in video frames, offering superior color accuracy and handling semi-transparent edges like hair or motion blur through sophisticated color and alpha channel predictions. The tool boasts features such as physically accurate unmixing for realistic composites, resolution independence supporting up to 4K footage, VFX standard outputs compatible with industry software (Nuke, Fusion, Resolve), and automatic cleanup of tracking markers and background elements. It is optimized for Linux systems equipped with NVIDIA RTX Pro 6000 or similar GPUs (24GB+ VRAM recommended) and also supports Windows with CUDA 12.6+. Installation is managed via uv, a modern Python package manager, with separate scripts for different operating systems to set up environments and download necessary models. Users can generate alpha hints through optional modules like GVM and VideoMaMa. The user interface includes a command-line wizard that facilitates configuration and processing of clips, supports various gamma spaces, despill strength adjustments, auto-despeckling, and refiner settings, with outputs encompassing raw alpha channels, straight color foregrounds, and premultiplied RGBA images. Advanced options allow backend selection between Torch (default) and MLX for Apple Silicon devices, along with device selection via CLI or environment variables. For troubleshooting and support, users can access community help on Discord and consult provided tips for common issues like missing checkpoints or backend errors. CorridorKey is free to use, even in commercial projects, but cannot be sold as a tool or API service; any modifications must remain open source with proper credit given to Corridor Key. The project encourages community involvement for further development while aiming to streamline green screen compositing by delivering precise and realistic keying solutions.
Keywords: #phi4, Alpha Hint, Apple Silicon, Apple SiliconKeywords: CorridorKey, CUDA, CorridorKey, Discord, EXR files, MLX, MPS, PyTorch, Python, VFX, VRAM, alpha channel, compositing, despill filter, green screen, inference, keying, licensing, neural network, open source, uv
github.com 3 days ago
|
696.
HN
My Homelab Setup
The author repurposed an old gaming PC from 2018 into a multi-functional homelab server using TrueNAS Community Edition, which now serves as a data storage hub, backup system for Fujifilm RAW files, and host for various self-hosted applications. The setup utilizes RAID 1 configuration with two 8 TB hard drives to ensure data redundancy by mirroring content across both drives while leveraging an SSD to enhance read/write speeds for specific services. TrueNAS's snapshot feature provides robust data recovery options through hourly to weekly backups that efficiently manage storage space by deleting outdated snapshots. A suite of applications is hosted on this server, including Scrutiny for drive health monitoring, Backrest for restic-based backups on Backblaze B2, Immich for organizing photos and videos with mobile app integration, Mealie for managing recipes, and Ollama for executing AI models like qwen3.5:4b.
To ensure secure remote access without exposing the server to public internet threats, Tailscale VPN is employed, utilizing WireGuard technology. Future enhancements are planned to streamline application accessibility by replacing direct IP address and port number use with custom domain names, enhancing ease of access and usability for users interacting with this versatile homelab setup.
Keywords: #phi4, AI models, Backrest, Fujifilm RAW, HDD, Homelab, Immich, Mealie, NAS, Ollama, RAID 1, SMART, SSD, Scrutiny, Tailscale, TrueNAS, VRAM, WireGuard, backups, data storage, domain names, self-hosting, snapshots
bryananthonio.com 3 days ago
https://www.borgbase.com 3 days ago
https://www.pikapods.com 3 days ago
https://www.youtube.com/watch?v=Inu5VhrO1rE 3 days ago
https://blog.mni.li/posts/internal-tls-with-caddy/ 3 days ago
https://nginx-wiki.getpagespeed.com/config/if-is-evil 3 days ago
https://tailscale.com/docs/features/tailscale-serv 2 days ago
https://www.amazon.com/ACEMAGICIAN-M1-Computers-Computer-3-2 2 days ago
https://portainer.myhome.top 2 days ago
https://jellyfin.myhome.top 2 days ago
http://127.0.0.1:8080 2 days ago
https://tailscale.com/docs/features/tailscale-serv 2 days ago
https://vermaden.wordpress.com/2024/04/20/tru 2 days ago
https://blog.gpkb.org/posts/homelab-2025/ 2 days ago
https://gist.github.com/evanpurkhiser/7663b7cabf82e6483 2 days ago
https://nginxproxymanager.com/ 2 days ago
http://service.mylocaldomain 2 days ago
https://tailscale.com/compare/wireguard 2 days ago
|
800.
HN
Designing a Game Board for the TMS9918A
The article explores the development of a game board for the TMS9918A graphics chip used in various retro computing systems, with particular emphasis on implementing the Lights Out puzzle. The author examines different design strategies adapted to each platform's unique capabilities and constraints. For instance, 2D arrays were employed for PICO-8, while byte-based representations with scratch memory bytes suited Atari 2600 and NES implementations. Windows ports used a single integer for efficiency, whereas platforms like C64 and ZX81 relied on implicit state through display updates.
The article also delves into the diverse display strategies dictated by hardware limitations: systems such as Atari 2600 and PICO-8 necessitated entire frame redraws each cycle, while others like Windows refreshed displays upon player moves. Input methods were similarly adapted to platform strengths, with home computers using labeled keyboards for cell inputs and consoles utilizing mouse or joystick controls.
The TMS9918A chip is highlighted for its superior flexibility in graphics handling compared to other platforms, facilitating VRAM access at any time and enabling detailed sprite usage. In terms of graphics modes, Graphics I mode relies on a default character set with restricted color assignments, whereas Graphics II mode provides bitmap-like functionality but requires creative approaches due to palette constraints.
The author discusses implementation considerations for efficiently mixing graphics modes—bitmap versus super-tile—to manage display elements such as logos and status lines while maintaining tile-based graphics for the game board. Finally, although further enhancements are conceivable, the focus is now shifting towards other projects, with existing implementations made available on GitHub for community use and exploration. This article underscores both the technical challenges and inventive solutions involved in adapting classic games to diverse hardware environments.
Keywords: #phi4, Atari 2600, Commodore 64, Graphics II mode, Lights Out, NES, PICO-8, RAM footprint, ROM space, TI-99/4A, TMS9900, TMS9918A, VIC-II, VRAM, Z80, ZX Spectrum, bit-level operations, bitmap, color palette, game board, graphics chip, joystick control, pattern table, sprite system, tilemap
bumbershootsoft.wordpress.com 3 days ago
|
1008.
HN
Qwen3.5-35B – 16GB GPU – 100T/s with 120K context AND vision enabled
The document offers a comprehensive guide on operating the Qwen3.5-35B model using NVIDIA GPUs with 16GB VRAM, focusing on optimizing local language processing speeds and multimodal capabilities. The Qwen3.5-35B-A3B variant is highlighted for achieving a performance of up to 125 tokens per second on consumer-grade hardware like RTX 5080/5090 GPUs, supporting full multimodal vision tasks. Performance optimization is achieved through the use of a native SM120 build for Blackwell series GPUs, which eliminates JIT warmup latency, allowing consistent high speeds from initial requests. A critical technical note involves a "context cliff" at 155,904 tokens where performance drops due to CUDA_Host buffer alignment issues rather than VRAM constraints.
Setup instructions detail the installation of `llama.cpp`, model weight acquisition via HuggingFace CLI, and Python-based performance benchmarking, emphasizing configuration adjustments to prevent speed degradation from excessive parallelism. The document specifies compatibility with multiple NVIDIA GPU generations (30xx/40xx/50xx series), outlining necessary system requirements for optimal operation.
In addition to text processing, the Qwen3.5-35B-A3B supports vision tasks such as image analysis and PDF reading without sacrificing speed, attributed to efficient mmproj handling. Effective GPU resource management is stressed, particularly on Windows systems, where extra VRAM may be required for stability when running concurrent applications.
The guide also encourages community involvement by sharing performance data across hardware setups to enhance collective understanding of the model's potential and limitations. It offers a suite of scripts, configuration files, and documentation aimed at fostering user engagement and experimentation with local large language models. This resource serves as an invaluable tool for both enthusiasts and professionals aiming to optimize language model performance on consumer-grade hardware, highlighting strategies for technical optimization and community collaboration.
Keywords: #phi4, Blackwell, CUDA, GPU, LLM, NVIDIA, PCIe, Qwen35-35B, RTX 5080, SM120Keywords: Qwen35-35B, VRAM, architecture, benchmarking, benchmarks, context, llamacpp, multimodal, performance, quantization, server, token cliff, vision
github.com 4 days ago
https://github.com/willbnu/Qwen-3.5-16G-Vram-Local 4 days ago
|
1321.
HN
Show HN: My first project, a native Win32/C++17 assistant with zero dependencies
NOVA 🌎 is a high-performance, native Win32/C++17 desktop assistant designed to provide reliability and efficiency with zero dependencies or bloat. It emphasizes user privacy by storing all data locally on the device. Leveraging EvolvingPersonality® technology, NOVA ensures persistent memory and identity growth across sessions, enhancing its adaptability and functionality over time.
Key features of NOVA include Universal Pathing for stable desktop and OneDrive path detection, an EXEC Engine that automates system management tasks via PowerShell and CMD scripts, and Multimodal Analysis capabilities using GDI+ to process various media types. Additionally, the Synchronous Boot feature ensures that the engine is ready before the user interface initializes.
NOVA functions as a software architect, executing precise commands through dual-execution protocols, enabling users to perform complex operations such as creating system info logs or compiling C++ code. It is compatible with Windows 10/11 (x64) systems and requires at least 8GB of VRAM for basic functionality, though 12GB or more is recommended for optimal performance. The software utilizes the MSVC compiler from Visual Studio versions 2019 or 2022.
The installation process involves running a series of batch files: `Setup_Nova.bat` to initialize the engine, `Save_Changes.bat` for environment checks and binary compilation, `Run_Nova.bat` to start NOVA, and `Create_Shortcut.bat` to generate a desktop shortcut. The application is developed by 94BILLY and can be found on [94billy.com/nova](http://94billy.com/nova).
Keywords: #phi4, API, Assistant, C++17, CMD, Compilation, Data Sovereignty, Desktop, GDI+, Identity Growth, MSVC, Multimodal Analysis, Nova, Orchestrator, Performance, PowerShell, Privacy, Processing, RTX 3060, Software Architect, Synchronous Boot, VRAM, Win32, Windows 10/11, Zero Dependencies
github.com 6 days ago
|
1541.
HN
Show HN: QLoRA fine-tuning in .zse INT4 format by ZSE
Version 1.4.0 of ZSE introduces support for QLoRA fine-tuning with INT4 models, enhancing training efficiency across various GPUs. The update is demonstrated through benchmarks using the H200 GPU and Qwen models, which showcase file sizes ranging from 5.57 GB to 41.21 GB and inference speeds varying between 6.3 to 37.2 tokens per second for model capacities of 7B to 72B. This version facilitates training different model sizes—specifically 7B, 32B, and 70B—on a range of GPUs including the RTX 3070/4070, RTX 3090/4090, A100-40GB, or dual 3090 setups. Users can fine-tune these models using a compact adapter approximately 25MB in size, constituting roughly 0.2% of model parameters (such as 12 million for a 7B model). Installation is streamlined through the command `pip install zllm-zse[training]`, with additional information and resources available on GitHub at github.com/zyora-ai/zse.
Keywords: #phi4, A100-40GB, GPU, GitHub, INT4, LoRAConfig, QLoRA, RTX 3070/4070, RTX 3090/4090, VRAM, ZSE, adapter, benchmarks, fine-tuning, inference, models, parameters, safetensors, speed, tok/s, tokenizer, training
news.ycombinator.com 7 days ago
|
1548.
HN
Where did my 128GB of video RAM go? AMD GPU BIOS gotcha for LLM builders
The author encountered an issue with their 128GB Ryzen AMD mini PC underperforming while running large language models (LLMs), initially noticing only 62GB of RAM usage due to how the system allocated memory between CPU and GPU in its integrated architecture. Upon investigation using Linux commands, they discovered that the default BIOS configuration assigned equal portions—64GB each—to graphics and system use, which was inefficient for their CPU-centric tasks. Contact with GMKTec confirmed this setup was optimized for gaming rather than AI workloads. To enhance performance, the author adjusted BIOS settings to allocate 96GB of VRAM to the GPU and 32GB to the host OS, aligning resources better with their needs. The article also touches on how model quantization affects LLM performance regarding quality and reliability, suggesting careful consideration in choosing model precision. Overall, it advises users with AMD integrated GPUs running self-hosted LLMs to modify memory allocations via BIOS settings to prioritize AI workloads over default graphics configurations.
Keywords: #phi4, AI infrastructure, AMD GPU, AMD Ryzen, BIOS, Docker containers, GMKTeck, LLM builders, Linux server, Ollama models, VRAM, amdgpu driver, firmware partition, inference quality, integrated GPU/CPU, performance degradation, quantization, resource allocation, sysfs files, unified memory, video RAM
patrickmccanna.net 7 days ago
https://strixhalo.wiki 7 days ago
|
1625.
HN
Qwen3.5 Fine-Tuning Guide – Unsloth Documentation
The Qwen3.5 Fine-Tuning Guide by Unsloth Documentation serves as an extensive manual for enhancing the performance of Qwen3.5 family models using the tool Unsloth, which is noted for improving training efficiency while reducing VRAM usage compared to FA2 configurations. The guide covers several critical aspects, including model support for sizes ranging from 0.8B to 122B, with capabilities for both text and reasoning-based fine-tuning tasks. It highlights that Unsloth enables models to train approximately 1.5 times faster using only half the VRAM of FA2 setups, though it notes that full fine-tuning requires significantly more resources.
The guide provides detailed information on VRAM requirements and setup procedures, including specific needs for BF16 LoRA configurations based on model size. It also offers instructions for updating Unsloth to accommodate users working with older versions or those conducting local fine-tuning. For Mixture of Experts (MoE) models like Qwen3.5-35B-A3B and 122B-A10B, it recommends using BF16 setups for optimal efficiency.
Regarding fine-tuning techniques, the guide suggests a minimal supervised recipe tailored to text-only tasks while advising users to keep dependencies updated, such as vision libraries and Transformers versions. It addresses out-of-memory issues by recommending adjustments in batch sizes or sequence lengths. For vision fine-tuning, it supports multimodal training with specific guidance on fine-tuning distinct components like vision layers or attention/MLP layers and managing multi-image inputs.
Additionally, the guide covers model exporting and saving using the GGUF format and includes steps for pushing models to Hugging Face. It also discusses common issues when models underperform in different runtimes, often due to incorrect chat templates or EOS tokens during inference. Lastly, it directs users to additional resources, including specific inference guides and Colab notebooks, facilitating practical experience with Qwen3.5 models. Overall, the documentation provides a thorough framework for optimizing and fine-tuning these language models across diverse configurations and scenarios.
Keywords: #phi4, Fine-tuning, GGUF, Google Colab, LLMs, LoRA, MoE, Qwen35, SFT, Transformers, Unsloth, VRAM, bf16, deployment, inference, multiGPUs, notebooks, reasoning, vLLM, vision fine-tuning
unsloth.ai 7 days ago
https://x.com/danielhanchen/status/197938989316506 7 days ago
https://cursor.com/blog/tab-rl 7 days ago
https://vercel.com/blog/v0-composite-model-family 7 days ago
https://docs.perplexity.ai/docs/getting-started/ov 7 days ago
https://careersatdoordash.com/blog/unleashing-the-power 7 days ago
https://earthdata.nasa.gov/news/nasa-ibm- 7 days ago
https://developers.openai.com/api/docs/guides/ 7 days ago
https://www.mercor.com/blog/expert-data-drives-model-pe 7 days ago
https://x.com/poezhao0605/status/20291519511670784 7 days ago
https://unsloth.ai/docs/models/qwen3.5/fine-t 7 days ago
https://blog.google/innovation-and-ai/technology/d 7 days ago
https://developers.googleblog.com/on-device-function-calling 7 days ago
https://pub.sakana.ai/doc-to-lora/ 7 days ago
https://www.youtube.com/watch?v=vxff_CnvPek 7 days ago
https://nehmeailabs.com/flashcheck 7 days ago
https://www.youtube.com/watch?v=eLDxXPziztw 6 days ago
https://tryolabs.com/blog/llms-leveraging-computer-visi 6 days ago
https://www.atredis.com/blog/2024/6/3/ho 6 days ago
https://huggingface.co/meta-llama/Meta-Llama-3-8B 6 days ago
https://github.com/huggingface/transformers/issues 6 days ago
https://huggingface.co/chenrm/qwen3-235b-a22b-h-corpus- 6 days ago
|
1663.
HN
Mac Has Hidden VRAM [video]
The YouTube video titled "Your Mac Has Hidden VRAM... Here's How to Unlock It" provides an exploration into methods for accessing and utilizing the hidden Video RAM (VRAM) in a Mac computer. The video appears to function as a tutorial or guide, suggesting techniques that could potentially enhance the performance of a Mac by making use of this often underutilized resource. Hosted on YouTube, the content adheres to standard policies of the platform, with copyright attributed to Google LLC as of 2026. This indicates an official recognition and dissemination of information through a widely-used digital channel, emphasizing its relevance for users interested in optimizing their Mac's capabilities by tapping into hidden VRAM resources.
Keywords: #phi4, Advertise, Contact, Copyright, Creators, Developers, Google, Google LLC Keywords: Mac, Hidden, Mac, NFL, Policy, Press, Privacy, Safety, Sunday Ticket, Terms, Unlock, VRAM, YouTube
www.youtube.com 7 days ago
|
1681.
HN
Intel Nova Lake-Ax for Local LLMs – Rumored AMD Strix Halo Competitor (2025)
The article explores the competitive dynamics in the development of high-performance APUs, focusing on Intel's rumored Nova Lake-AX chip, which is intended to rival AMD's Strix Halo in supporting large local language models (LLMs). Intel’s Nova Lake-AX promises enhanced computational power and memory bandwidth through its 384 Xe3P execution units and faster LPDDR5X memory. However, the project faces potential delays until 2027, during which AMD could advance with the Medusa Halo, leveraging a wider memory bus and next-generation LPDDR6 memory to potentially outperform Intel's offering. Although Intel aims to provide substantial theoretical advantages for LLMs, actual effectiveness will hinge on architectural efficiency and software optimization. This ongoing competition underscores the evolving landscape of APUs dedicated to improving local AI processing capabilities, highlighting the strategic moves by both Intel and AMD in this rapidly advancing technological field.
Keywords: #phi4, AMD, APUs, CPU cores, FP32 cores, GPU, Intel, LLMs, LPDDR5X, Medusa Halo, Nova Lake-AX, RDNA 35, ROCm, Strix Halo, VRAM, Xe3P architecture, compute power, memory bandwidth, memory bus, software drivers, token generation
www.hardware-corner.net 7 days ago
|
2061.
HN
Show HN: ZSE – Single-file LLM engine with dual INT4 kernels
ZSE is a streamlined Large Language Model (LLM) inference engine designed for simplicity and efficiency, featuring a single-file format (.zse) that integrates the model, tokenizer, and configuration, thereby eliminating network calls during loading and supporting offline use. It employs dual INT4 kernels—namely ZSE Kernel and ZSE bnb Kernel—to optimize performance across different hardware environments. The architecture supports intelligent layer selection to maximize hardware efficiency and is especially beneficial for fast cold starts in serverless deployments. Benchmark tests conducted on the H200 using Qwen 2.5 illustrate that ZSE Kernels manage various model sizes with specific VRAM usage, processing speeds measured in tokens per second (tok/s), and cold start times; for example, a 7B model consumes 5.67 GB of VRAM, processes at 37 tok/s, and starts up in 5.7 seconds using the ZSE Kernel.
For installation, users can utilize pip with the command `pip install zllm-zse`, and they have the option to convert models for use through commands like `zse convert`. The tool is publicly available on GitHub at [Zyora-Dev/zse](https://github.com/Zyora-Dev/zse), where users are encouraged to provide feedback. For communication regarding inquiries or suggestions, contact details are sought to facilitate further interaction.
Keywords: #phi4, GitHub, INT4, INT4 kernels, LLM, LLM engine, VRAM, ZSE, benchmarks, cold starts, dual kernel, dual kernel backend, efficiency, feedback Keywords: ZSE, hardware optimization, offline, pip install, serverless, serverless deployments, simplicity, tok/s, zse file format
github.com 9 days ago
|
2124.
HN
A misconception I had about OpenClaw
The author reflects on their initial misconceptions about OpenClaw, noting that Mac Minis are typically used for iMessage and API calls rather than running agents locally. They discuss experimenting with an AMD Radeon RX6700XT GPU, which achieved moderate success in language model tasks via Ollama and Open WebUI, though not surpassing a MacBook's M4 chip. The author questions the necessity of investing in specific hardware when utilizing large language models (LLMs) like Qwen, Gemini, ChatGPT, or Claude, expressing skepticism about relying on LLMs for tasks that might be more efficiently completed manually with precise prompts and Google searches.
Despite OpenClaw's popularity on GitHub, the author contemplates whether running local models is beneficial compared to using powerful hosted alternatives. They express intrigue yet caution regarding the concept of agents and potential future programming dependencies on a few tech companies. An anecdote about Summer Yue deleting her inbox via OpenClaw highlights LLMs' limitations and emphasizes personal data security concerns. Overall, the author maintains a skeptical but curious stance towards AI's evolving role in programming and daily tasks, recognizing both its promises and current constraints.
Keywords: #phi4, AMD Radeon RX6700XT3, API, GitHub stars, Linux kernel, M4, Mac mini, Ollama, Open WebUI, OpenClaw, Summer Yue, VRAM, agents, env, eternal promise, hackintosh, iMessage, llm hallucination, misconception, opencode, programming, prompt, qwen, x the everything app
nathanielkaiser.xyz 9 days ago
|
2526.
HN
Accuracy vs. Speed in Local LLMs: Finding Your Sweet Spot
The article explores the balance between accuracy and speed when using Local Large Language Models (LLMs) for different applications, emphasizing that the optimal model selection depends on hardware capabilities, specific use cases, and context requirements. A central theme is the trade-off between high-accuracy models, which demand more memory and processing power, and faster models that may sacrifice reasoning depth or long-context handling. Recommendations are provided based on this balance: Tongyi DeepResearch 30B-A3B excels in accuracy with its high-precision quantization, while Qwen3-Coder-Next is noted for a favorable accuracy/speed trade-off, especially effective on mid-range GPUs for coding tasks. For rapid data scraping, Nemotron-3-Nano-30B-A3B-GGUF offers the fastest inference times. Additionally, THUDM/GLM-4.7-Flash-Q4_K_M and Qwen/Qwen3-Coder-Next-Q3_K_S are acknowledged for their accuracy despite variable performance. For tasks involving long contexts, models such as gpt-oss-20b or Nvidia Nemotron 30B A3B are recommended, potentially necessitating configuration adjustments. Community insights highlight the importance of optimized quantization, Mixture of Experts (MoE) behavior, and correct configuration settings to achieve desired speed and stability. Ultimately, no single model fits all scenarios; selection should be based on specific hardware and application needs, with Tongyi DeepResearch 30B-A3B, Qwen3-Coder-Next GGUFs, and Nemotron-3-Nano-30B-A3B-GGUF being suggested starting points for varied tasks.
Keywords: #phi4, Accuracy, CUDA, Coding, Community Signals, Compute, Context Window, GGUF, Hardware, Huggingface, Inference, Llamacpp, Local LLMs, MoE (Mixture of Experts), Nemotron-3-Nano, OpenCode, Quantization, Qwen3-Coder-Next, Reasoning, Reddit, Scraping, Speed, Tongyi DeepResearch, Use Case, VRAM
grigio.org 11 days ago
|
2869.
HN
30k Peptides and a GPU That Wasn't Trying Hard Enough
In February, Carolina Cloud partnered with Apexomic, a bioinformatics company, to improve the generation of peptide designs using their tool, BoltzGen, by leveraging GPU acceleration through cloud services. Initially utilizing dual GTX 1080 GPUs, Apexomic aimed to generate 30,000 peptide designs over a weekend but encountered performance limitations. The transition to Carolina Cloud's RTX 5090 GPU resulted in a significant increase in processing speed, achieving a fivefold improvement for the critical design step by optimizing batch processing settings.
While this enhancement boosted GPU efficiency, CPU-bound steps like Analysis remained slower due to resource constraints on cloud infrastructure. To address these challenges, Carolina Cloud offered seamless container resizing, enabling Apexomic to dynamically allocate additional vCPUs and RAM without data loss or reinstallation, thereby enhancing overall performance. This flexibility was instrumental in meeting project deadlines efficiently.
The collaboration underscored the significance of maintaining a balanced GPU-CPU system for scientific AI tasks and demonstrated how dynamic resource management can markedly impact results. It highlighted Carolina Cloud's ability to provide flexible, responsive support and resources tailored to complex computational needs, illustrating its strengths in facilitating efficient scientific research processes.
Keywords: #phi4, AMD EPYC 7742, Apexomic, BoltzGen, CPU, CUDA cores, GPU, GTX 1080, Peptides, R&D, RTX 5090, VRAM, bioinformatics, cloud computing, computational biology, container resizing, data analytics, hybrid compute, molecular design, neural network inference, peptide diffusion trajectories, performance optimization, pipeline execution, scientific AI
carolinacloud.substack.com 13 days ago
|
3224.
HN
TinyTTS: Ultra-light English TTS (9M params, 20MB), 8x CPU, 67x GPU
TinyTTS is an ultra-lightweight Text-to-Speech (TTS) system designed to operate efficiently in resource-constrained environments, including edge devices or scenarios where GPU resources are heavily used by large language models. It features a compact model with approximately 9 million parameters and a disk footprint of around 20 MB, enabling rapid audio generation—approximately eight times real-time on CPUs and sixty-seven times faster on GPUs such as the RTX 4060. The system's low VRAM requirement of under 126 MB further enhances its suitability for edge applications. Aimed at overcoming the resource-heavy demands typical of traditional TTS frameworks in local voice assistant setups, TinyTTS is self-contained and easily integrated via a straightforward Python API or command-line interface, which automatically fetches necessary model files from Hugging Face upon first use.
Developed under the Apache 2.0 license, TinyTTS encourages community accessibility and collaboration. The developer has plans to release training code for user-friendly fine-tuning in the future, alongside potential enhancements like zero-shot voice cloning. Installation is streamlined via pip directly from its GitHub repository, supporting both Python and command-line interfaces for speech generation. As the project continues to evolve, user feedback is welcomed to guide further development.
Keywords: #phi4, CPU, English, GPU, GitHub ```, GitHub ``` TinyTTS, Gradio, Gradio Web Demo, Hugging Face, Python API, TTS framework, TinyTTS, VRAM, edge devices, parameters, voice cloning, zero-shot, zero-shot voice cloning
news.ycombinator.com 14 days ago
|

{kind=link}